笔记应用:wolai和notion
最近发现了这两个生产力神器,功能类似(可以很方便的构建自己的知识图谱或者是追踪个人的计划及执行情况), 特性上各有千秋,wolai的中文支持更好,notion的多媒体支持更丰富。以后这个blog的功能应该会更加单纯,需要与更多人分享的内容才会发出来,个人知识管理类的直接wolai走起,不会再发出来了~
EAI的工作交付完成后有一段时间空闲期,没有实际的活儿,和浩哥一起学了一些程序分析相关的东西。浩哥技术不错,也乐于组织一些技术分享,经常带着我们一群编译器小白讲解概念和“结对编程”(其实是边写代码边给我们将思路)。这期间最大的收获就是学了一些source 2 source转换和ANTLR的一些知识。记得当时准备一个链接器专利需要自动改写linker script,于是准备用ANTLR做source 2 source的转换,但是当时能找到的只有一个ANTLR2 语法的linker script语法文件,为了让ANTLR4的运行时能正确解析,还套娃去找了一个将ANTLR2语法文件转换成ANTLR4语法文件的工具hhh。
空闲的状态没有持续太久,我们组就打包卖给海思图灵去写vector core和scalar core的算子。我当时主要是负责vector core算子的编写,vector core开发用的是TIK(Tensor Iterator Kernel), 是一个Python开发框架,框架会将我们写的TIK代码转换为CCE-C代码,然后用CCE-C的编译器编译出device侧的二进制。开发流程十分传统厚重,感受了一把原汁原味的瀑布式开发流程,每个算子实现都要写概要设计文档、详细设计文档,然后设计文档也有集体检视,文档检视还有缺陷率的要求(>5%)。
负责实现的第一个算子是SGBM,用于作双目视差计算的,最高需要支持1080p的灰度图作为输入。这个算法比较复杂,主要分为4个步骤:
算法根据上面步骤分给了三个人做,我主要负责动态规划部分的实现。动态规划计算时,每个像素依赖当前行和上一行中的像素,但是无法一次容纳最大size的两行像素。因此我们需要同时对行和列进行tiling切分,每次处理两行x64个像素,先从左向右传播,后从上向下传播。这样的tiling切分会导致host到device的数据搬运和后续处理的流水线效率不高,最后算法整体测试时结果也验证了这一点。但这是算法特性(下一行依赖上一行)决定的,最后算法要不要异构下放到vector core这个需求又回去重新评估了。。
后面又负责了WarpAffine和WarpPerspective两个算子的实现,这两个算子数学公式看起来都很简单,只是简单的双线性内插值。但是OpenCV的实现却用了3000行+,其中用到了很多巧妙的优化小技巧,例如对小方格进行量化切分成NxN的小格,每个格子中直接存放了周围四个像素点的权重。这两个算法分析好优化方案之后就无甚可书了,tiling按照行搬入即可,写到最后我的代码补全工具比我还要懂TIK,写几个字母能直接补全一两行。
ME(Mindspore前端)的主要工作之前已经汇总过了,可以看这篇。
趁着这段时间有空,将在公司的经历记录一下,一者是趁着还有印象留个纪念,二者是为这段时间和以后的面试理理思绪。
EAI框架是进公司的第一个项目,内容的话是实现一个包含经典机器学习推理算法+科学计算的纯C(Cython也算上)的框架,几个刚进公司连C都没怎么写过的小年轻硬莽出来的。经典机器学习算法的话主要是包含KNN、谱聚类、SVD、Ensemble Learning这些算法,目标是对比scikit-learn等python库在公司Arm平台实现5x+的加速(全靠对手衬托…); 科学计算的部分的话,主要是一些numpy格式矩阵的转置等操作、各种插值算法,最离谱也是我印象最深的是对glibc里log10函数的加速哈哈。
这里ensemble learning算法的弱模型都是基于决策树的,更具体的来说包含:random forest,isolated forest,AdaBoost, GBDT。scikit-learn里这些算法的决策树最后都是调用到Cython的实现,所以其实基准性能也不算太差。
上面提到的几种算法在训练的时候各有不同,但在推理的时候极其相似:都是把数据(feature vector)喂给决策树,得到一个值(回归值、深度等);然后将每个决策树得到的值以某种方式组合起来(平均值、加权平均等),得到最终的值。
每棵树的推理过程都可以理解成下面过程:
1 | float TreeInfer(float* x, Node* nodes) { |
推理的过程非常简单,算法层面的优化不大,优化主要是从访存和并行两方面入手。
上面naive实现的代码中容易看到,每个决策树推理的过程中,下一个节点的位置依赖于模型中的阈值和输入的数据,无法提前预知。因此,上面的实现容易造成大量的cache miss,访存局部性较差。
为了解决上面的访存问题,Quick Scorer(paper)算法通过对模型中阈值按feature分组,每个组内的阈值预先排序,然后使用一些巧妙的bit representation实现了顺序访问也能找到输入feature vector在每棵决策树中对应的叶子节点。
具体做法如下:
对于一个输入feature vector和一棵选定的决策树,树中的内部节点(inner nodes)可以根据它们所包含的feature threshold T与feature value V的大小关系划分为两组:True Nodes和False Nodes。如下图所示,True Nodes表示 V < T的节点,False Nodes表示V >= T的节点。
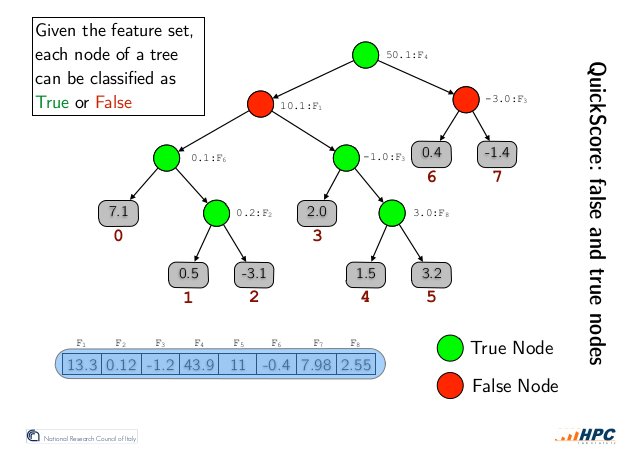
推论0:True Nodes只有右子树中的节点可能被访问到(candidates); False Nodes只有左子树中的节点可能被访问到。
推论1: True Nodes的左子树不可能被访问到,可以安全的被排除出candidates;False Nodes可以安全的排除右子树
作者利用推论1设计了一种内部节点的bit representation(见下图):每个内部节点有一个长为叶子节点个树的bitvector,从左到右每个bit对应从左到右每个叶子节点,不可能访问到的标记为0,可能访问到的标记为1(candidates,NOTE:不属于当前节点左右子树的节点也是candidates)。
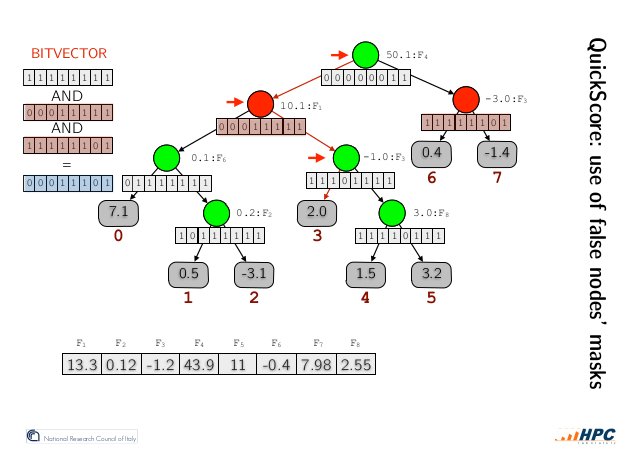
如上图所示,我们在所有False Nodes的candidates中取交集(bit and operation),从左往右第一个candidate便是我们要找的叶子节点。
Why? 目标节点在交集中显而易见,那么为什么是从左往右第一个呢?
分两种情况讨论,
Q.E.D.
如此,以任意顺序访问节点来进行推理成为了可能。那么,如何快速得到所有False Nodes呢?答案就是上文提到的,对模型中的阈值,按照feature分组并在推理前做好排序即可。优化后推理流程中,模型的主要数据结构的访问都由原来的随机访存,变为了线性或者稀疏线性,访存性能得到了一定程度的提升。
框架推理接口同时提供C接口和Cython暴露出来的python接口,接口中输入为多个样本,我们选择了进行数据并行多线程加速。值得注意的时,Python中让人头疼的GIL,在调用C实现时可以比较容易的绕过。
一开始这个工具只是为了个人开发测试用,于是快速手橹了几个python脚本,把模型序列化成json格式,反序列化则是从头手写的json解析器。后面得知这玩意儿要作为交付件交付,无知者无畏就这么交付了,但凡有一个大哥带,也不会不用上protobuf-c啥的。。
二次插值比较简单,三次样条插值需要自己解线性方程组,问题规模不是很大,只是实现了简单的高斯消元求解。然后印象比较深刻的就是,三次样条插值的边界条件默认设置是”not-a-knot”, 这只指定了一个方程,要使方程有唯一解还需要一个额外的边界条件,找遍了scipy的源码也没找到怎么设置的,最后是试错才找到的。。
这个需求是某业务部门profiling之后发现的性能瓶颈之一,计算log10竟然占到了所有计算时间的超过10%。log10作为glibc数学库中的一部分,自然本身的实现也是不差的,优化谈何容易,但是好在互联网上有各色好心人分享自己的智慧。一番搜寻之后,找到了一个ebay的工程师写的博客,讲的是他优化log2实现的过程,里面涉及的知识面十分广。文中讲到的几个大点至今还有印象,IEEE 754浮点数的定义可以帮助我们快速用位操作计算log2;log2的计算有许多近似公式可以选择,选择近似公式既要考虑速度由要考虑公式在各种情况下的数值稳定性;选择好一个近似公式之后,公式中的各个参数如何通过凸优化求解。最后实现出来的log10比glibc快2倍多,给大神递可乐orz
中间还穿插做了一个小工具,可以用于裁剪python库。这个裁剪工具根据粒度的不同分两部分,第一个部分是文件级的裁剪,根据应用的使用情况裁剪掉库中不需要的各种文件。原理比较简单,运行一个大佬用Go写的用户态文件系统,这个文件系统会统计每个文件的访问次数,裁剪脚本(python实现)以此作为判断是否需要的依据,删掉不需要的文件。另一个部分是函数级裁剪,一个文件中也会有许多用不到的函数,同样可以裁剪掉。
看稚晖君的视频用墨水屏显示图像的部分提到了这个算法,感觉很有意思。墨水屏或者黑白打印机只能显示二值的黑白像素,dithering算法能帮我们用黑白近似灰度图像。其实,更一般地,dithering算法可以用来平滑各种信号量化带来的误差。
考虑将灰度图像(0为全黑,255为全白)量化为黑白图片,灰度值为42时我们如何量化呢?简单的做法是取灰度上的近邻,用0来表示灰度值为42的像素。对于量化产生的误差,如果直接忽略,最后生成的图像质量会很差,因此我们需要找到更好的处理量化误差的方式。
error diffusion dithering算法以某种顺序处理像素,处理像素时的量化误差在迭代处理像素时扩散(diffusion)。例如:当前像素为42,量化为0的误差为42,假设下一个像素值为100,那么加上传递过来的误差等于142,此像素应该量化为1,此时误差变为142 - 255 = -113,继续向下一个像素传递,以此类推。
缺点:原图中的色块会扩散为黑色的线。
上面线性的处理的一个意想(liao)不(zhi)到(zhong)的后果(artifacts)就是会导致生成图像中奇怪的条纹。核心的原因就是2D图像采用了1D的误差扩散方式。
从左上角向右下角扩散,局部涉及的像素和系数表如下:
| X | 7/16 | |
|---|---|---|
| 3/16 | 5/16 | 1/16 |
同样是左上角向右下角扩散,设计的像素和系数表如下:
| X | 7/48 | 5/48 | ||
|---|---|---|---|---|
| 3/48 | 5/48 | 7/48 | 5/48 | 3/48 |
| 1/48 | 3/48 | 5/48 | 3/48 | 1/48 |
很多其他的扩散方式可以选择,but you get the idea.
准备用manimgl渲染一些数学释义,配置tex的过程折腾了一番,记录一下备忘。
1 | pip install tex |
算是重拾LLVM,这次重头记录学习历程。
安装比较简单,apt-get直接安装即可:
1 | sudo apt-get install clang |
使用LLVM CookBook里的一个小例子验证安装是否成功。
demo code:
1 | define i32 @test1(i32 %A) { |
testfile.llopt工具中指令合并的pass:opt -S -instcombine testfile.ll -o output1.llopt -S -deadargelim testfile.ll -o output2.ll我们容易通过查看上面运行pass后的输出代码确认pass已生效:
output1.ll:
1 | ; ModuleID = 'tesetfile.ll' |
output2.ll:
1 | ; ModuleID = 'testfile.ll' |
对于我这种容易分心的人,有限的精力很容易被看起来有趣的事情骗走。但是要做一只卓有成效的社畜,有长远的目标并为之专注是必须的。最近看到一个巴菲特的目标管理方式,感觉很有启发,记录并用起来。
故事最原始的出处没有查证,随手找了一个版本。大意是,我们都有很多的目标,花时间将其中对我们来说最重要的整理出来是很值得的。首先,我们可以整理出对我们最重要的25个目标。但我们精力有限,显然不可能同时追求这些目标,可以再从这25个目标中选出对我们来说最重要的5个形成一个短名单。
对于这样两个目标列表的使用容易陷入一个误区:优先追求对我们最重要的5个目标,剩下的20个目标放于次要的优先级,等我们有空再去花精力。但是巴菲特告诉我们,我们要尽力避免在剩下的20个目标上花任何精力。因为正是这些次要目标才是最容易让我们分心浪费掉精力的,因为他们会给我们错误的激励(那些我们完全不感兴趣的目标反而不会)。
知易行难,小目标理起来~
公司内网看到一个提升C++代码性能的模式(源头是这篇blog),能够以一种容易维护的方式很大程度提升访存的局部性,感觉挺有意思,记录一下。
假设你的系统需要打开大量的路径(文件、sockets,pipes),对于这些路径你需要打开、处理、关闭对应的文件描述符并取消文件描述符和对应路径之间的联系。
对于这样的需求,我们可能写出下面的代码:
1 | class UnlinkingFD { |
每个打开的路径对应一个上面的对象保存对应的路径和文件描述符,大量的打开的文件描述符可能以UnlinkingFD对象形式保存在数组中。上面的代码在功能和逻辑上是完好的,RAII也会在对象生命周期结束时关掉文件描述符并取消和对应路径之间的关联。
假设我们经常需要用到fd,但是path只在对象生命周期结束时使用。因为一个上面的UnlinkingFD对象需要占用40Bytes,而我们常用的fd只占用了其中的4Bytes,这意味着我们在访问UnlinkingFD数组时cache miss的概率大大提升。
将array-of-structs变为struct-of-arrays,这当然可以帮助提升性能,但是我们将无法使用RAII来帮我们做资源管理,单一的fd无法及时得到释放。
UnlinkingFD对象中不直接保存string对象,而是使用一个unique_ptr指针。这样一个UnlinkingFD对象就从40Bytes降低到了16Bytes,降低了cache miss的概率。
OutOfLine模式可以帮我们将像path这样的冷数据完全移到对象之外,但是仍然保留RAII为我们管理资源。
OutOfLine类是一个静态多态的基类。 使用此基类时要传入两个模板参数,第一个模板参数为继承的子类,第二个模板参数为要挂在“热”对象上的冷数据的类型。
例如,对于上面的UnlinkingFD类,改写后的用法如下:
1 | struct UnlinkingFD : private OutOfLine<UnlinkingFD, std::string> { |
OutOfLine模式将冷数据从对象中剥离出去的思路时通过一个全局对象将“热”对象的指针和冷数据关联起来。
1 | template <class FastData, class ColdData> |
静态继承自OutOfLine类的UnlinkingFD现在只有4Bytes, 因此需要高频访问的UnlinkingFD对象的数组的cache miss被降到最低。同时RAII会同时替我们管理“热”数据对象及对应的冷数据。
上面静态继承的过程实际上一定程度上限定了热数据和冷数据构造的顺序,因为C++构造函数初始化的顺序如下:
因此,当我们构造一个“热”数据对象时,会首先构造OutOfLine基类(此时OutOfLine类的构造函数中会构造冷数据对象),然后构造“热”数据对象。这就意味着冷数据对象的构造不能依赖于“热”数据对象。
当冷数据对象的初始化依赖于热数据对象时,我们需要hack一下初始化的顺序。方法如下:为OutOfLine静态基类提供一个特别的构造函数,这个构造函数以tag类TwoPhaseInit为入参。当我们调用这个构造函数时,冷数据不会被初始化,此时处于一种半构造的状态。然后我们在“热”数据初始化之后显式的调用init_cold_data来初始化冷数据。释放时同理可以引入release_cold_data来hack析构的顺序。代码如下:
1 | struct TwoPhaseInit {}; |
OutOfLine代码1 |
|
1 | // g++ --std=c++1z -Wall -Wextra -O3 -o ool_benchmark ool_benchmark.cpp |
注意map的try_emplace方法是C++17引入的新特性,编译命令如下:g++ benchmark.cpp -o benchmark -std=c++17。在我自己的笔记本上运行的结果如下:
1 | With cold data in-line (original) took 82936589ns and 3350498669 is a value I don't want optimized away |
加速效果没有原始博客中的那么大,但付出的成本近乎免费,因此在性能优化时是很值得考虑的一个选项。
最近工作需要用到Pybind11 class绑定中一些较为高级的特性(虚函数、重载、继承),在此整理记录一下。
class绑定对应上一篇中的第一种场景,即将C++原生类型通过class_函数向Python暴露。下面用一个小例子展示class绑定最基本的用法:
1 |
|
上面的代码向Python暴露了Pet类,其中有三个方法:__init__, setName, getName。
在def函数时可以添加参数的名字及设置默认值。
1 |
|
设置默认值类似(NOTE: C++接口中定义的默认值不会自动捕获,需要bind时设置):
1 | PYBIND11_MODULE(example, m) { |
上面的方法绑定是将Python方法绑定到方法指针上,实际上可以用Lambda函数替换。例如,给Pet类增加一个__repr__方法:
1 | py::class_<Pet>(m, "Pet") |
C++中公有成员变量可以绑定为Python中可以读写的attributes(const成员绑定为只读attributes),例如:
1 | PYBIND11_MODULE(example, m) { |
私有成员变量可以通过绑定C++中的getter和setter成为Python中的property:
1 | py::class_<Pet>(m, "Pet") |
类似的方法还有:def_readwrite_static(), def_readonly_static(), def_property_static(), def_property_readonly_static()
NOTE: Python可以动态的添加属性,绑定时也可以使能C++暴露的类在Python中支持动态属性:
1 | // py::dynamic_attr()支持动态属性 |
C++中的继承关系有两种方式保留到暴露到Python的类中,下面以一个例子说明。
1 | struct Pet { |
第一种方法是子类暴露时在class_的模板中指定基类
1 | py::class_<Pet>(m, "Pet") |
第二种方法是在子类暴露时在class_的参数中传入基类的class_闭包
1 | py::class_<Pet> pet(m, "Pet"); |
自动向下类型转换指的是多态类型的基类指针形式返回子类对象,此指针被自动识别并转换为子类的指针。需要注意的是,上面的Pet和Dog并不是多态类型,因为Pet中没有定义虚函数。
下面以Pet和Dog为例展示没有自动downcasting时的行为:
1 | // 返回指向子类对象的基类指针 |
我们可以向Pet中添加一个虚函数来通知Pybind11这种多态关系:
1 | struct PolymorphicPet { |
C++中重载的方法直接通过方法名取指针会有歧义,Pybind11有两种方法消除这种歧义。
1 | struct Pet { |
1 | struct Pet { |
直接以例子来说明:
1 | class Animal { |
我们可以在C++中新增一个跳转类来解决上述问题
1 | class PyAnimal : public Animal { |
NOTE: 用Python类扩展C++暴露出来的类时,不要使用super(), 不要使用super(), 不要使用super()! 应该直接使用对应类的__init__方法, 因为Python的方法解析顺序(MRO)和C++不一致。
继续直接从例子开始
1 | class Animal { |
NOTE: 上面通过pybind11注册过的类的子类都需要定义跳转类来覆写父类中的虚函数,当子类较多或者虚函数较多时,可以使用模板类来避免大量重复代码(参考这里)。
使用py::init<Args, ...>()或者py::init_alias<Args, ...>()绑定构造函数较方便,但有时我们需要绑定自定义的方法作为构造函数(例如:工厂方法,单例获取静态方法)。
下面的代码展示多种将C++方法绑定为Python构造函数的途径:
1 | class Example { |
两种方法:
py::init<>提供两个工厂函数,第一个在不需要子类时调(即暴露的类只在Python中被使用而没有被继承),第二个在需要子类时被调用两种方式的demo如下:
1 |
|
在class_的模板参数中指定所有的基类即可:
1 | py::class_ <MyType, BaseType1, BaseType2, BaseType3>(m, "MyType") |