工作总结0: EAI框架
趁着这段时间有空,将在公司的经历记录一下,一者是趁着还有印象留个纪念,二者是为这段时间和以后的面试理理思绪。
EAI框架是进公司的第一个项目,内容的话是实现一个包含经典机器学习推理算法+科学计算的纯C(Cython也算上)的框架,几个刚进公司连C都没怎么写过的小年轻硬莽出来的。经典机器学习算法的话主要是包含KNN、谱聚类、SVD、Ensemble Learning这些算法,目标是对比scikit-learn等python库在公司Arm平台实现5x+的加速(全靠对手衬托…); 科学计算的部分的话,主要是一些numpy格式矩阵的转置等操作、各种插值算法,最离谱也是我印象最深的是对glibc里log10函数的加速哈哈。
Ensemble Learning
这里ensemble learning算法的弱模型都是基于决策树的,更具体的来说包含:random forest,isolated forest,AdaBoost, GBDT。scikit-learn里这些算法的决策树最后都是调用到Cython的实现,所以其实基准性能也不算太差。
上面提到的几种算法在训练的时候各有不同,但在推理的时候极其相似:都是把数据(feature vector)喂给决策树,得到一个值(回归值、深度等);然后将每个决策树得到的值以某种方式组合起来(平均值、加权平均等),得到最终的值。
每棵树的推理过程都可以理解成下面过程:
1 | float TreeInfer(float* x, Node* nodes) { |
推理的过程非常简单,算法层面的优化不大,优化主要是从访存和并行两方面入手。
访存优化:Quick Scorer算法
上面naive实现的代码中容易看到,每个决策树推理的过程中,下一个节点的位置依赖于模型中的阈值和输入的数据,无法提前预知。因此,上面的实现容易造成大量的cache miss,访存局部性较差。
为了解决上面的访存问题,Quick Scorer(paper)算法通过对模型中阈值按feature分组,每个组内的阈值预先排序,然后使用一些巧妙的bit representation实现了顺序访问也能找到输入feature vector在每棵决策树中对应的叶子节点。
具体做法如下:
对于一个输入feature vector和一棵选定的决策树,树中的内部节点(inner nodes)可以根据它们所包含的feature threshold T与feature value V的大小关系划分为两组:True Nodes和False Nodes。如下图所示,True Nodes表示 V < T的节点,False Nodes表示V >= T的节点。
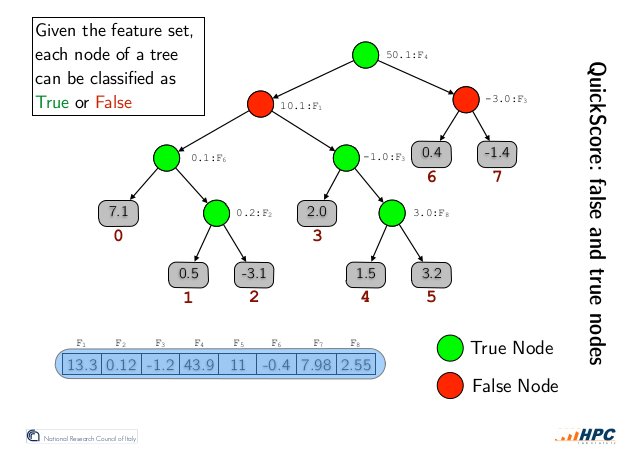
推论0:True Nodes只有右子树中的节点可能被访问到(candidates); False Nodes只有左子树中的节点可能被访问到。
推论1: True Nodes的左子树不可能被访问到,可以安全的被排除出candidates;False Nodes可以安全的排除右子树
作者利用推论1设计了一种内部节点的bit representation(见下图):每个内部节点有一个长为叶子节点个树的bitvector,从左到右每个bit对应从左到右每个叶子节点,不可能访问到的标记为0,可能访问到的标记为1(candidates,NOTE:不属于当前节点左右子树的节点也是candidates)。
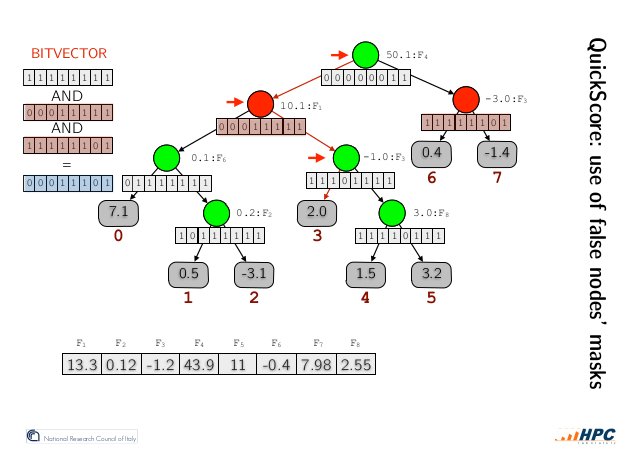
如上图所示,我们在所有False Nodes的candidates中取交集(bit and operation),从左往右第一个candidate便是我们要找的叶子节点。
Why? 目标节点在交集中显而易见,那么为什么是从左往右第一个呢?
分两种情况讨论,
- 结果的bit vector中没有0,那么显而易见就是决策通路上全是True Nodes,也就是走到了第1个叶子节点,满足我们的结论。
- 结果的bit vector中有0,那么从左往右第一个False Node必然在决策通路中(更左的False Node如果存在会导致第一个1左移),对此节点也作两种情况讨论:
- 此节点右子树直接连接叶子节点,显然满足我们的结论。
- 此节点右子树不直接连接叶子节点,则后续决策通路全为True Nodes(如果直接连接的右子节点为False Node, 则按上面的求并集的过程,第一个0会右边移动,所以直接右子节点为True Node, and so on and so forth), 也就是说决策通路通往的就是此节点的第一个candidate,满足我们的结论。
Q.E.D.
如此,以任意顺序访问节点来进行推理成为了可能。那么,如何快速得到所有False Nodes呢?答案就是上文提到的,对模型中的阈值,按照feature分组并在推理前做好排序即可。优化后推理流程中,模型的主要数据结构的访问都由原来的随机访存,变为了线性或者稀疏线性,访存性能得到了一定程度的提升。
并行
框架推理接口同时提供C接口和Cython暴露出来的python接口,接口中输入为多个样本,我们选择了进行数据并行多线程加速。值得注意的时,Python中让人头疼的GIL,在调用C实现时可以比较容易的绕过。
模型序列化和反序列化
一开始这个工具只是为了个人开发测试用,于是快速手橹了几个python脚本,把模型序列化成json格式,反序列化则是从头手写的json解析器。后面得知这玩意儿要作为交付件交付,无知者无畏就这么交付了,但凡有一个大哥带,也不会不用上protobuf-c啥的。。
插值算法: 二次插值,样条插值
二次插值比较简单,三次样条插值需要自己解线性方程组,问题规模不是很大,只是实现了简单的高斯消元求解。然后印象比较深刻的就是,三次样条插值的边界条件默认设置是”not-a-knot”, 这只指定了一个方程,要使方程有唯一解还需要一个额外的边界条件,找遍了scipy的源码也没找到怎么设置的,最后是试错才找到的。。
log10加速
这个需求是某业务部门profiling之后发现的性能瓶颈之一,计算log10竟然占到了所有计算时间的超过10%。log10作为glibc数学库中的一部分,自然本身的实现也是不差的,优化谈何容易,但是好在互联网上有各色好心人分享自己的智慧。一番搜寻之后,找到了一个ebay的工程师写的博客,讲的是他优化log2实现的过程,里面涉及的知识面十分广。文中讲到的几个大点至今还有印象,IEEE 754浮点数的定义可以帮助我们快速用位操作计算log2;log2的计算有许多近似公式可以选择,选择近似公式既要考虑速度由要考虑公式在各种情况下的数值稳定性;选择好一个近似公式之后,公式中的各个参数如何通过凸优化求解。最后实现出来的log10比glibc快2倍多,给大神递可乐orz
其他
中间还穿插做了一个小工具,可以用于裁剪python库。这个裁剪工具根据粒度的不同分两部分,第一个部分是文件级的裁剪,根据应用的使用情况裁剪掉库中不需要的各种文件。原理比较简单,运行一个大佬用Go写的用户态文件系统,这个文件系统会统计每个文件的访问次数,裁剪脚本(python实现)以此作为判断是否需要的依据,删掉不需要的文件。另一个部分是函数级裁剪,一个文件中也会有许多用不到的函数,同样可以裁剪掉。