I = np.eye(d) inhibit = 1 - I B = 1. / tau_model A = (-k * I - beta * inhibit) / tau_model
with nengo.Network(label="LCA") as net: net.input = nengo.Node(size_in=d) # array of ensembles: d ensembles, each with n_neurons neurons x = nengo.networks.EnsembleArray( n_neurons, d, eval_points=nengo.dists.Uniform(0., 1.), intercepts=nengo.dists.Uniform(0., 1.), encoders=nengo.dists.Choice([[1.]]), label="state") # transform: linear transformation mapping the pre output to the post input # synapse: synapse model for filtering nengo.Connection(x.output, x.input, transform=tau_actual * A + I, synapse=tau_actual) nengo.Connection(net.input, x.input, transform=tau_actual*B, synapse=tau_actual) net.output = x.output return net
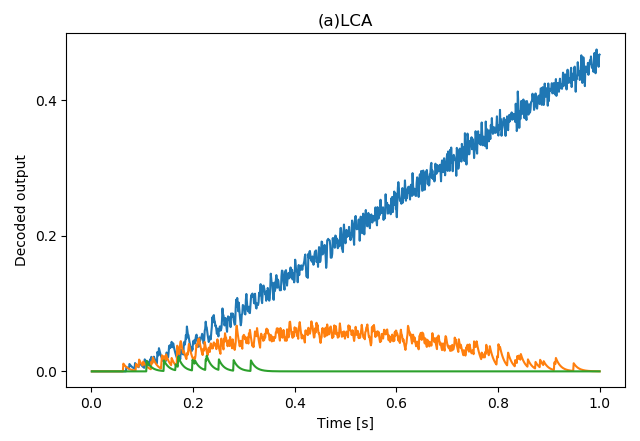
defmain(): dt = 0.001 with nengo.Network(seed=42) as model: # winner takes all wta = LCA(3, 200, dt) stimulus = nengo.Node([0.8, 0.7, 0.6]) nengo.Connection(stimulus, wta.input, synapse=True)
p_stimulus = nengo.Probe(stimulus, synapse=None) p_output = nengo.Probe(wta.output, synapse=0.01) with nengo.Simulator(model, dt=dt) as sim: sim.run(1.)
import matplotlib.pyplot as plt import numpy as np import nengo from nengo.utils.matplotlib import rasterplot
from nengo.dists import Uniform
model = nengo.Network(label="A Single Neuron") with model: neuron = nengo.Ensemble(1, dimensions=1, intercepts=Uniform(-.5, -.5), max_rates=Uniform(100, 100), encoders=[[1]]) # input node cos = nengo.Node(lambda t: np.cos(8*t)) nengo.Connection(cos, neuron) cos_probe = nengo.Probe(cos) # 神经元原始脉冲输出 spikes = nengo.Probe(neuron.neurons) # 细胞体电压 voltage = nengo.Probe(neuron.neurons, "voltage") # spikes filtered by a 10ms post-synaptic filter filtered = nengo.Probe(neuron, synapse=0.01)
with nengo.Simulator(model) as sim: sim.run(1) # plot the decoded output of the ensemble plt.figure() plt.plot(sim.trange(), sim.data[filtered]) plt.plot(sim.trange(), sim.data[cos_probe]) plt.xlim(0, 1)
# plot the spiking output of the ensemble plt.figure(figsize=(10, 8)) plt.subplot(221) rasterplot(sim.trange(), sim.data[spikes]) plt.ylabel("Neuron") plt.xlim(0, 1)
# plot the soma voltages of the neurons plt.subplot(222) plt.plot(sim.trange(), sim.data[voltage][:,0], 'r') plt.xlim(0, 1) plt.show()
int a = 42; int b = 43; // a, b 均为左值 a = b; b = a; // a + b 为右值 int c = a + b; a + b = 42; // error! // 不能对右值取地址 a = foo(); // ok, foo() is a rvalue int* p = &foo(); // invalid, 不能对右值取地址